| Record Information |
|---|
| Version | 5.0 |
|---|
| Status | Detected and Quantified |
|---|
| Creation Date | 2006-08-13 13:57:36 UTC |
|---|
| Update Date | 2023-02-21 17:16:57 UTC |
|---|
| HMDB ID | HMDB0004194 |
|---|
| Secondary Accession Numbers | |
|---|
| Metabolite Identification |
|---|
| Common Name | N1-Methyl-4-pyridone-3-carboxamide |
|---|
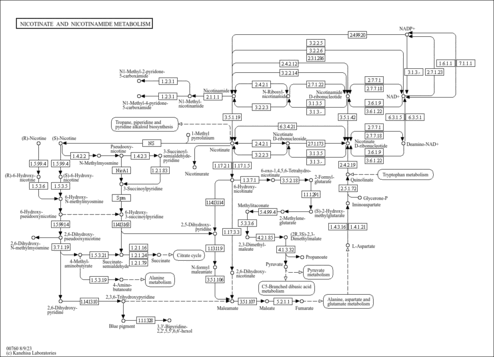
| Description | N1-Methyl-4-pyridone-3-carboxamide, also known as 5-aminocarbonyl-1-methyl-4(1H)-pyridone, belongs to the class of organic compounds known as nicotinamides. These are heterocyclic aromatic compounds containing a pyridine ring substituted at position 3 by a carboxamide group. NN1-Methyl-4-pyridone-3-carboxamide (4PY ) is a normal human metabolite (one of the end products of nicotinamide-adenine dinucleotide (NAD) degradation). N1-Methyl-4-pyridone-3-carboxamide is an extremely weak basic (essentially neutral) compound (based on its pKa). N1-methyl-4-pyridone-3-carboxamide can be biosynthesized from 1-methylnicotinamide; which is mediated by the enzyme aldehyde oxidase. In humans, N1-methyl-4-pyridone-3-carboxamide is involved in nicotinate and nicotinamide metabolism. N1-Methyl-4-pyridone-3-carboxamide is a potentially toxic compound. Uremic toxins tend to accumulate in the blood either through dietary excess or through poor filtration by the kidneys. As a uremic toxin, this compound can cause uremic syndrome. |
|---|
| Structure | InChI=1S/C7H8N2O2/c1-9-3-2-6(10)5(4-9)7(8)11/h2-4H,1H3,(H2,8,11) |
|---|
| Synonyms | | Value | Source |
|---|
| 1,4-Dihydro-1-methyl-4-oxo-3-pyridinecarboxamide | ChEBI | | 1-Methyl-4-oxo-1,4-dihydro-3-pyridinecarboxamide | ChEBI | | 1-Methyl-4-pyridone-3-carboximide | ChEBI | | 1-Methyl-4-pyridone-5-carboxamide | ChEBI | | 3-(Aminocarbonyl)-1-methyl-4(1H)-pyridone | ChEBI | | 5-Aminocarbonyl-1-methyl-4(1H)-pyridone | ChEBI | | N'-methyl-4-pyridone-5-carboxamide | ChEBI | | N-Methyl-4-pyridone-5-carboxamide | ChEBI | | N1-Methyl-4-pyridone-5-carboxamide | ChEBI | | 1-Methyl-4-pyridone-3-carboxamide | HMDB |
|
|---|
| Chemical Formula | C7H8N2O2 |
|---|
| Average Molecular Weight | 152.1506 |
|---|
| Monoisotopic Molecular Weight | 152.05857751 |
|---|
| IUPAC Name | 1-methyl-4-oxo-1,4-dihydropyridine-3-carboxamide |
|---|
| Traditional Name | 1-methyl-4-oxopyridine-3-carboxamide |
|---|
| CAS Registry Number | 769-49-3 |
|---|
| SMILES | CN1C=CC(=O)C(=C1)C(N)=O |
|---|
| InChI Identifier | InChI=1S/C7H8N2O2/c1-9-3-2-6(10)5(4-9)7(8)11/h2-4H,1H3,(H2,8,11) |
|---|
| InChI Key | KTLRWTOPTKGYQY-UHFFFAOYSA-N |
|---|
| Chemical Taxonomy |
|---|
| Description | Belongs to the class of organic compounds known as nicotinamides. These are heterocyclic aromatic compounds containing a pyridine ring substituted at position 3 by a carboxamide group. |
|---|
| Kingdom | Organic compounds |
|---|
| Super Class | Organoheterocyclic compounds |
|---|
| Class | Pyridines and derivatives |
|---|
| Sub Class | Pyridinecarboxylic acids and derivatives |
|---|
| Direct Parent | Nicotinamides |
|---|
| Alternative Parents | |
|---|
| Substituents | - Nicotinamide
- Dihydropyridine
- Hydropyridine
- Vinylogous amide
- Heteroaromatic compound
- Carboxamide group
- Primary carboxylic acid amide
- Cyclic ketone
- Carboxylic acid derivative
- Azacycle
- Organooxygen compound
- Organonitrogen compound
- Organopnictogen compound
- Organic oxygen compound
- Organic nitrogen compound
- Organic oxide
- Hydrocarbon derivative
- Aromatic heteromonocyclic compound
|
|---|
| Molecular Framework | Aromatic heteromonocyclic compounds |
|---|
| External Descriptors | |
|---|
| Ontology |
|---|
| Physiological effect | |
|---|
| Disposition | |
|---|
| Process | |
|---|
| Role | |
|---|
| Physical Properties |
|---|
| State | Solid |
|---|
| Experimental Molecular Properties | | Property | Value | Reference |
|---|
| Melting Point | Not Available | Not Available | | Boiling Point | Not Available | Not Available | | Water Solubility | Not Available | Not Available | | LogP | Not Available | Not Available |
|
|---|
| Experimental Chromatographic Properties | Not Available |
|---|
| Predicted Molecular Properties | |
|---|
| Predicted Chromatographic Properties | Predicted Collision Cross SectionsPredicted Kovats Retention IndicesUnderivatizedDerivatized| Derivative Name / Structure | SMILES | Kovats RI Value | Column Type | Reference |
|---|
| N1-Methyl-4-pyridone-3-carboxamide,1TMS,isomer #1 | CN1C=CC(=O)C(C(=O)N[Si](C)(C)C)=C1 | 1665.2 | Semi standard non polar | 33892256 | | N1-Methyl-4-pyridone-3-carboxamide,1TMS,isomer #1 | CN1C=CC(=O)C(C(=O)N[Si](C)(C)C)=C1 | 1815.1 | Standard non polar | 33892256 | | N1-Methyl-4-pyridone-3-carboxamide,1TMS,isomer #1 | CN1C=CC(=O)C(C(=O)N[Si](C)(C)C)=C1 | 2070.1 | Standard polar | 33892256 | | N1-Methyl-4-pyridone-3-carboxamide,2TMS,isomer #1 | CN1C=CC(=O)C(C(=O)N([Si](C)(C)C)[Si](C)(C)C)=C1 | 1716.2 | Semi standard non polar | 33892256 | | N1-Methyl-4-pyridone-3-carboxamide,2TMS,isomer #1 | CN1C=CC(=O)C(C(=O)N([Si](C)(C)C)[Si](C)(C)C)=C1 | 1847.3 | Standard non polar | 33892256 | | N1-Methyl-4-pyridone-3-carboxamide,2TMS,isomer #1 | CN1C=CC(=O)C(C(=O)N([Si](C)(C)C)[Si](C)(C)C)=C1 | 2009.1 | Standard polar | 33892256 | | N1-Methyl-4-pyridone-3-carboxamide,1TBDMS,isomer #1 | CN1C=CC(=O)C(C(=O)N[Si](C)(C)C(C)(C)C)=C1 | 1922.1 | Semi standard non polar | 33892256 | | N1-Methyl-4-pyridone-3-carboxamide,1TBDMS,isomer #1 | CN1C=CC(=O)C(C(=O)N[Si](C)(C)C(C)(C)C)=C1 | 2013.0 | Standard non polar | 33892256 | | N1-Methyl-4-pyridone-3-carboxamide,1TBDMS,isomer #1 | CN1C=CC(=O)C(C(=O)N[Si](C)(C)C(C)(C)C)=C1 | 2210.6 | Standard polar | 33892256 | | N1-Methyl-4-pyridone-3-carboxamide,2TBDMS,isomer #1 | CN1C=CC(=O)C(C(=O)N([Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C)=C1 | 2202.4 | Semi standard non polar | 33892256 | | N1-Methyl-4-pyridone-3-carboxamide,2TBDMS,isomer #1 | CN1C=CC(=O)C(C(=O)N([Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C)=C1 | 2236.1 | Standard non polar | 33892256 | | N1-Methyl-4-pyridone-3-carboxamide,2TBDMS,isomer #1 | CN1C=CC(=O)C(C(=O)N([Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C)=C1 | 2209.4 | Standard polar | 33892256 |
|
|---|
| GC-MS Spectra| Spectrum Type | Description | Splash Key | Deposition Date | Source | View |
|---|
| Predicted GC-MS | Predicted GC-MS Spectrum - N1-Methyl-4-pyridone-3-carboxamide GC-MS (Non-derivatized) - 70eV, Positive | splash10-0zg0-4900000000-20331ed897c9e0a9fc31 | 2017-09-01 | Wishart Lab | View Spectrum | | Predicted GC-MS | Predicted GC-MS Spectrum - N1-Methyl-4-pyridone-3-carboxamide GC-MS (Non-derivatized) - 70eV, Positive | Not Available | 2021-10-12 | Wishart Lab | View Spectrum |
MS/MS Spectra| Spectrum Type | Description | Splash Key | Deposition Date | Source | View |
|---|
| Experimental LC-MS/MS | LC-MS/MS Spectrum - N1-Methyl-4-pyridone-3-carboxamide 30V, Positive-QTOF | splash10-0006-9200000000-1cb822771a6ad4a05575 | 2021-09-20 | HMDB team, MONA | View Spectrum | | Experimental LC-MS/MS | LC-MS/MS Spectrum - N1-Methyl-4-pyridone-3-carboxamide 0V, Positive-QTOF | splash10-0udr-0900000000-1d0361e9faeabeb71262 | 2021-09-20 | HMDB team, MONA | View Spectrum | | Experimental LC-MS/MS | LC-MS/MS Spectrum - N1-Methyl-4-pyridone-3-carboxamide 10V, Positive-QTOF | splash10-000i-0900000000-6f959701aa7326eb0c63 | 2021-09-20 | HMDB team, MONA | View Spectrum | | Experimental LC-MS/MS | LC-MS/MS Spectrum - N1-Methyl-4-pyridone-3-carboxamide 0V, Positive-QTOF | splash10-0udr-0900000000-208827e4de225e9d8d63 | 2021-09-20 | HMDB team, MONA | View Spectrum | | Experimental LC-MS/MS | LC-MS/MS Spectrum - N1-Methyl-4-pyridone-3-carboxamide 10V, Positive-QTOF | splash10-000i-0900000000-f55ef59743379eae48ba | 2021-09-20 | HMDB team, MONA | View Spectrum | | Experimental LC-MS/MS | LC-MS/MS Spectrum - N1-Methyl-4-pyridone-3-carboxamide 30V, Positive-QTOF | splash10-0006-9200000000-ae1cfccb1887632aa147 | 2021-09-20 | HMDB team, MONA | View Spectrum | | Experimental LC-MS/MS | LC-MS/MS Spectrum - N1-Methyl-4-pyridone-3-carboxamide 20V, Positive-QTOF | splash10-000i-4900000000-63099c0a130f1a93fd19 | 2021-09-20 | HMDB team, MONA | View Spectrum | | Experimental LC-MS/MS | LC-MS/MS Spectrum - N1-Methyl-4-pyridone-3-carboxamide 10V, Positive-QTOF | splash10-000i-0900000000-081f0ec3c9d46b1b3bd8 | 2021-09-20 | HMDB team, MONA | View Spectrum | | Experimental LC-MS/MS | LC-MS/MS Spectrum - N1-Methyl-4-pyridone-3-carboxamide 30V, Positive-QTOF | splash10-0006-9200000000-050f4f2282bac4a4ede9 | 2021-09-20 | HMDB team, MONA | View Spectrum | | Experimental LC-MS/MS | LC-MS/MS Spectrum - N1-Methyl-4-pyridone-3-carboxamide 40V, Positive-QTOF | splash10-0006-9000000000-39816589e8ae9e5f8604 | 2021-09-20 | HMDB team, MONA | View Spectrum | | Predicted LC-MS/MS | Predicted LC-MS/MS Spectrum - N1-Methyl-4-pyridone-3-carboxamide 10V, Positive-QTOF | splash10-0udi-0900000000-584bee8b1d116d28ad72 | 2016-08-01 | Wishart Lab | View Spectrum | | Predicted LC-MS/MS | Predicted LC-MS/MS Spectrum - N1-Methyl-4-pyridone-3-carboxamide 20V, Positive-QTOF | splash10-0w2i-0900000000-9b1ca159ad8a687a6449 | 2016-08-01 | Wishart Lab | View Spectrum | | Predicted LC-MS/MS | Predicted LC-MS/MS Spectrum - N1-Methyl-4-pyridone-3-carboxamide 40V, Positive-QTOF | splash10-0ab9-9500000000-8c23a4085269713574de | 2016-08-01 | Wishart Lab | View Spectrum | | Predicted LC-MS/MS | Predicted LC-MS/MS Spectrum - N1-Methyl-4-pyridone-3-carboxamide 10V, Negative-QTOF | splash10-0udi-0900000000-fdc0b46552431f575ba6 | 2016-08-03 | Wishart Lab | View Spectrum | | Predicted LC-MS/MS | Predicted LC-MS/MS Spectrum - N1-Methyl-4-pyridone-3-carboxamide 20V, Negative-QTOF | splash10-0pb9-2900000000-280bfbe85df4a0da0894 | 2016-08-03 | Wishart Lab | View Spectrum | | Predicted LC-MS/MS | Predicted LC-MS/MS Spectrum - N1-Methyl-4-pyridone-3-carboxamide 40V, Negative-QTOF | splash10-0pbc-9200000000-ca4c67126b692467c9ee | 2016-08-03 | Wishart Lab | View Spectrum | | Predicted LC-MS/MS | Predicted LC-MS/MS Spectrum - N1-Methyl-4-pyridone-3-carboxamide 10V, Positive-QTOF | splash10-000i-0900000000-7d7c2fb30321be106dba | 2021-09-22 | Wishart Lab | View Spectrum | | Predicted LC-MS/MS | Predicted LC-MS/MS Spectrum - N1-Methyl-4-pyridone-3-carboxamide 20V, Positive-QTOF | splash10-052r-0900000000-5da27f9f442b311a97fc | 2021-09-22 | Wishart Lab | View Spectrum | | Predicted LC-MS/MS | Predicted LC-MS/MS Spectrum - N1-Methyl-4-pyridone-3-carboxamide 40V, Positive-QTOF | splash10-0a59-9500000000-02d654c5564e7e65df73 | 2021-09-22 | Wishart Lab | View Spectrum | | Predicted LC-MS/MS | Predicted LC-MS/MS Spectrum - N1-Methyl-4-pyridone-3-carboxamide 10V, Negative-QTOF | splash10-0udi-0900000000-222319115ca49603e9d0 | 2021-09-23 | Wishart Lab | View Spectrum | | Predicted LC-MS/MS | Predicted LC-MS/MS Spectrum - N1-Methyl-4-pyridone-3-carboxamide 20V, Negative-QTOF | splash10-0a4i-0900000000-2682511e81f9b8e4a101 | 2021-09-23 | Wishart Lab | View Spectrum | | Predicted LC-MS/MS | Predicted LC-MS/MS Spectrum - N1-Methyl-4-pyridone-3-carboxamide 40V, Negative-QTOF | splash10-0zfr-9200000000-ecbc5d1685a2efb1bb50 | 2021-09-23 | Wishart Lab | View Spectrum |
NMR Spectra| Spectrum Type | Description | Deposition Date | Source | View |
|---|
| Predicted 1D NMR | 13C NMR Spectrum (1D, 100 MHz, D2O, predicted) | 2021-09-24 | Wishart Lab | View Spectrum | | Predicted 1D NMR | 1H NMR Spectrum (1D, 100 MHz, D2O, predicted) | 2021-09-24 | Wishart Lab | View Spectrum | | Predicted 1D NMR | 13C NMR Spectrum (1D, 1000 MHz, D2O, predicted) | 2021-09-24 | Wishart Lab | View Spectrum | | Predicted 1D NMR | 1H NMR Spectrum (1D, 1000 MHz, D2O, predicted) | 2021-09-24 | Wishart Lab | View Spectrum | | Predicted 1D NMR | 13C NMR Spectrum (1D, 200 MHz, D2O, predicted) | 2021-09-24 | Wishart Lab | View Spectrum | | Predicted 1D NMR | 1H NMR Spectrum (1D, 200 MHz, D2O, predicted) | 2021-09-24 | Wishart Lab | View Spectrum | | Predicted 1D NMR | 13C NMR Spectrum (1D, 300 MHz, D2O, predicted) | 2021-09-24 | Wishart Lab | View Spectrum | | Predicted 1D NMR | 1H NMR Spectrum (1D, 300 MHz, D2O, predicted) | 2021-09-24 | Wishart Lab | View Spectrum | | Predicted 1D NMR | 13C NMR Spectrum (1D, 400 MHz, D2O, predicted) | 2021-09-24 | Wishart Lab | View Spectrum | | Predicted 1D NMR | 1H NMR Spectrum (1D, 400 MHz, D2O, predicted) | 2021-09-24 | Wishart Lab | View Spectrum | | Predicted 1D NMR | 13C NMR Spectrum (1D, 500 MHz, D2O, predicted) | 2021-09-24 | Wishart Lab | View Spectrum | | Predicted 1D NMR | 1H NMR Spectrum (1D, 500 MHz, D2O, predicted) | 2021-09-24 | Wishart Lab | View Spectrum | | Predicted 1D NMR | 13C NMR Spectrum (1D, 600 MHz, D2O, predicted) | 2021-09-24 | Wishart Lab | View Spectrum | | Predicted 1D NMR | 1H NMR Spectrum (1D, 600 MHz, D2O, predicted) | 2021-09-24 | Wishart Lab | View Spectrum | | Predicted 1D NMR | 13C NMR Spectrum (1D, 700 MHz, D2O, predicted) | 2021-09-24 | Wishart Lab | View Spectrum | | Predicted 1D NMR | 1H NMR Spectrum (1D, 700 MHz, D2O, predicted) | 2021-09-24 | Wishart Lab | View Spectrum | | Predicted 1D NMR | 13C NMR Spectrum (1D, 800 MHz, D2O, predicted) | 2021-09-24 | Wishart Lab | View Spectrum | | Predicted 1D NMR | 1H NMR Spectrum (1D, 800 MHz, D2O, predicted) | 2021-09-24 | Wishart Lab | View Spectrum | | Predicted 1D NMR | 13C NMR Spectrum (1D, 900 MHz, D2O, predicted) | 2021-09-24 | Wishart Lab | View Spectrum | | Predicted 1D NMR | 1H NMR Spectrum (1D, 900 MHz, D2O, predicted) | 2021-09-24 | Wishart Lab | View Spectrum |
IR Spectra| Spectrum Type | Description | Deposition Date | Source | View |
|---|
| Predicted IR Spectrum | IR Ion Spectrum (Predicted IRIS Spectrum, Adduct: [M-H]-) | 2023-02-03 | FELIX lab | View Spectrum | | Predicted IR Spectrum | IR Ion Spectrum (Predicted IRIS Spectrum, Adduct: [M+H]+) | 2023-02-03 | FELIX lab | View Spectrum | | Predicted IR Spectrum | IR Ion Spectrum (Predicted IRIS Spectrum, Adduct: [M+Na]+) | 2023-02-03 | FELIX lab | View Spectrum |
|
|---|



{kind=link}